- Visual Data Storytelling
- Posts
- [VDS] 7 Tips I Would Have Given Me In 2023
[VDS] 7 Tips I Would Have Given Me In 2023
7 software engineering tips every data scientists should know about in 2024.
Mathieu Guglielmino
January 01, 2024

7 Tips I Would Have Given Me In 2023
A digest more focused on code and software this first day of 2024.
A virtual environment serves as an isolated instance of Python, and you can have as many as you want on your machine.
It's handy for keeping track of what a project needs, and it's a good idea to use one whenever you're starting something new.

Once the virtual environment is sourced, your terminal should display (venv) before the commands you type:

This requirements.txt is only a list of installed packages with version (pandas==2.1.4), and makes it easy to share the dependencies of your code without sending out the Python libs.
You can install all the packages from the requirements.txt file in a fresh virtual environment with the -r flag of pip install:

For notebook lovers, you may recall you run your Python code in what is called a “Kernel”. You may want the Python from the kernel and the one from your virtual env to be the same one:

Run the ipykernel command in your virtual env to make it accessible in Jupyter as the my_project kernel.
Exploratory data analysis is an emergent activity, so it’s hard to know in advance what you may find out.
However, I always check for my data columns at checkpoints:
after I load the data (
data_loaded),after processing (
data_proc),before I create charts (
data_charts),before I write the data somewhere (
data_output)
In Python this can be done with the assert keyword. Assuming your data is a pandas dataframe:

If the expression returns false, an AssertionError is generated.
Tests make you write cleaner and more modular code, which improves readability and maintainability, and they provide a common understanding of how your code should behave.
If you want to write tests, in Python you have the choice:

Logs are at the center of any monitoring factory. For data manipulation, you may want to record somewhere, like in a file, the steps of your pipeline and eventual errors.
Handlers such as logging.FileHandler or logging.StreamHandler are useful to output the logs to the stream and / or to file:

There are no excuses not to write docstrings in 2024.
Documentation is seamlessly integrated in most code editors, such as VS Code, and it’s never been easier to ask ChatGPT to write the docstring of a function.
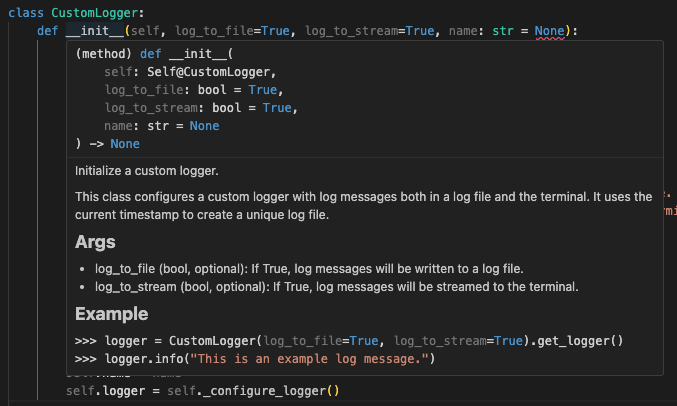
This is the docstring of the previous CustomLogger class, with clear formatting and usage example:

You shouldn’t bury the parameters of your pipeline directly in the code, but rather write self-explanatory configuration files, lightweight and easy to share.
While JSON is a commonly used file format, it comes with certain drawbacks that make it less ideal compared to YAML:
Human-Readable Syntax: YAML uses indentation and relies on whitespace for structure, making it more readable and visually appealing to humans;
Minimal Punctuation: YAML requires fewer punctuation characters compared to JSON;
Comments Support: YAML supports comments, allowing explanatory notes directly in the configuration file.

I usually have a Config class that I adapt for each project:

Design systems document the looks of what you build.
Nothing looks more by-default than the default colors of matplotlib
If you use Python, you can keep a constants.py and define a color palette, or a dictionary of colors for some ominous business categories you chart all the time:

If you’re not familiar with design systems, you can take a look at The Economist Visual Styleguide.
You can also check the following visual reviews of 2023:
See you next week,
Mathieu Guglielmino
Reply